The San Diego Safari Park has one of the world’s most successful
cheetah breeding programs. To support this, they keep track of their
cheetahs’ characteristics. For each cheetah, the Safari Park keeps track
of:
Whether color of the cheetah’s fur; golden or
dark.
The length of the cheetah’s claws; short or
long.
The cheetah’s development; whether it is young,
adolescent, or mature.
We’re given the following information about the cheetahs in the
park:
A new cheetah is observed with dark fur and
short claws. Assuming conditional independence of
features (color, length) within a class (development), calculate the
probability that this cheetah is young using Bayes’
Theorem. In this question, you may leave your answers unsimplified, in
terms of fractions, exponents, factorials, the permutation formula P(n, k), and the binomial coefficient {n \choose k}.
\frac{7}{13}
To calculate the probability that a cheetah is young given that it
has dark fur and short claws we can use Bayes’ Theorem!
We first need to calculate: P(\text{Dark
Fur} \cap \text{Short Claws} | \text{Young}).
We can do this using the equation: P(\text{Dark Fur} \cap \text{Short Claws} |
\text{Young}) = P(\text{Dark Fur} | \text{Young}) \cdot P(\text{Short
Claws} | \text{Young}).
Notice the denominator of our Bayes’ Theorem is P(\text{Dark Fur} \cap \text{Short Claws})
this means we need to probability of seeing Dark Fur or Short Claws
regardless of the development stage.
This follows the equation for the law of total probability:
This means we need to calculate: P(\text{Dark Fur} \cap \text{Short Claws} |
\text{Adolescent}) and P(\text{Dark
Fur} \cap \text{Short Claws} | \text{Mature}).
Information about a sample of 50
cheetahs in the San Diego Safari Park is summarized in the table
below.
Golden Fur
Dark Fur
Sum of Row
Short Claws
Long Claws
Short Claws
Long Claws
Young
2
0
10
4
16
Adolescent
6
3
2
6
17
Mature
3
12
0
2
17
Sum of Column
11
15
12
12
50
For instance, we’re told that 10
cheetahs with dark fur and short claws are young and that there were
11 cheetahs with golden fur and short
claws.
Given its other characteristics, San Diego Safari Park would like to
use this information to predict whether a new cheetah to the Park is
young, adolescent, or mature.
A new cheetah is observed with golden fur and
long claws. Using the data in the table and assuming
conditional independence of features, use the Naive Bayes formula
with smoothing to determine which developmental stage
is most likely for the new cheetah. In this question, you may leave your
answers unsimplified, in terms of fractions, exponents, factorials, the
permutation formula P(n, k), and the
binomial coefficient {n \choose k}.
Mature
To figure out if the new cheetah is young, adolescent, or mature we
need to find the probabilities for each stage of development.
This means we need to find the probability of a young cheetah having
golden fur and long claws, the probability of a adolenscent cheetah
having golden fur and long claws, and the probability of a mature
cheetah having golden fur and long claws.
Let Age represent either Young, Adolescent, or Mature. We need to
then follow the equation: P(\text{Age}|\text{Golden Fur} \cap \text{Long
Claws}) = P(\text{Age}) \cdot P(\text{Golden Fur}|\text{Age}) \cdot
P(\text{Long Claws}|\text{Age}) for all the different ages.
Recall we will also be using smoothing! This means:
P(\text{Feature}|\text{Class}) =
\frac{\text{Count of Features in Class} + 1}{\text{Total in Class} +
\text{Number of Possible Feature Values}}
Consider three events A, B, and
C in the same sample space.
Problem 3.1
Which of the following is equivalent to P((A\cap B)|(B \cap C))? Select all
that apply.
P(A|(B \cap C))
P(A \cap B \cap C)
P((B \cap C)|(A \cap B))
P((A \cap C)|(B \cap C))
None of the above.
P(A|(B \cap C)) and P((A \cap C)|(B \cap C))
Recall the formula for conditional probability is P(A|B) = \frac{P(A \cap B)}{P(B)}. We are
going to use this fact to figure out which of the following are the same
as P((A\cap B)|(B \cap C)).
We should first expand P((A\cap B)|(B \cap
C)) by doing: P((A\cap B)|(B \cap C)) =
\frac{P(A \cap B) \cap P(B \cap C)}{P(B \cap C)}. We can further
simplify the numerator to be (A \cap B) \cap
(B \cap C) \rightarrow A \cap B \cap C. This means we get P((A\cap B)|(B \cap C)) by doing: P((A\cap B)|(B \cap C)) = \frac{P(A \cap B \cap
C)}{P(B \cap C)}.
Now we can go through each of the options and figure out if, when put
inside the formula for conditional probability, we get \frac{P(A \cap B \cap C)}{P(B \cap C)}.
Since options 1 and 4 are correct the answer cannot be None of
the Above!
Problem 3.2
Suppose P((A \cap B)|C) = P(A|(B \cap
C))*P(B). Which of the following pairs of events must be
independent?
A, B
A, C
B, C
None of the above.
B, C
We are going to rewrite the following in the hopes of being able to
simplify things later. To do this we will once again use the formula for
conditional probability: P(A|B) = \frac{P(A
\cap B)}{P(B)}
Let’s look at the left side of P((A \cap
B)|C) = P(A|(B \cap C))*P(B).
Let’s now look at the right side of P((A
\cap B)|C) = P(A|(B \cap C))*P(B).
P(A|(B \cap C))*P(B) = \frac{P(A)P(B \cap
C)}{P(B \cap C)} * P(B) = \frac{P(A \cap B \cap C)}{P(B \cap C)}* P(B) =
\frac{P(A \cap B \cap C) * P(B)}{P(B \cap C)}
Now we can look at them together! \frac{P(A
\cap B \cap C)}{P(C)} = \frac{P(A \cap B \cap C) * P(B)}{P(B \cap
C)}. We can cross multiply to clear the fractions: P(A \cap B \cap C) * P(B \cap C) = P(A \cap B \cap
C) * P(B) * P(C). Assuming that P(A
\cap B \cap C) \neq 0 we can divide both sides by P(A \cap B \cap C). We end up with P(B \cap C) = P(B) * P(C), which demonstrates
to us that B and C are independent of one another.
Suppose that there are three possible experience levels in chess
(beginner, intermediate, advanced). Only 10% of
beginner players beat Avi at a game of chess, while 50%
of intermediate players and 80% of advanced players
do.
Avi signs up to participate in a certain chess tournament called the
Avocado Cup. Aside from Avi, 50% of the players in the
tournament are beginners, 40% are intermediate, and
10% are advanced.
The tournament proceeds in rounds. In the first round of the
tournament, players are randomly paired up for a game
of chess.
Problem 4.1
What is the probability that Avi wins in the first round of the
tournament?
33 \%
50 \%
67 \%
83 \%
None of the above.
67 \%
We know the percentages of players that beat Avi (meaning Avi loses)
and the percentages of different types of players inside the Avocado
Cup.
We can use the percentage of players that beat Avi to figure out the
percentage of times Avi wins by writing 1 -
p.
Avi wins against beginners with a likelihood of 1 - 0.1 = 0.9, against intermediate players
with a likelihood of 1 - 0.4 = 0.6, and
against advanced players with a likelihood of 1 - 0.8 = 0.2.
Now we can multiply the probabilities of Avi winning with their
respective probabilities of different players’ types to find the
probability Avi that will win in the first round! We can do this because
you can imagine we are multiplying the probability Avi wins with the
amount of people in the tournament of that level.
It turns out that, sadly, Avi loses to his opponent in the first
round. What is the probability that Avi’s opponent is an advanced
player? Choose the closest answer among the choices
listed.
15 \%
25 \%
35 \%
45 \%
25 \%
Let P(A) be the probability of Avi
playing against an advanced player
Let P(B) be the probability of Avi
losing a match
Let P(C) be the probability of Avi
playing against an intermediate player
Let P(D) be the probability of Avi
playing against a beginner player
We can use Bayes’ theorem to help us find the probability that Avi
lost the match to an advanced player (P(A|B)). Recall Bayes’ theorem is:
P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)}
We are given the probability that Avi loses the match against an
advanced player P(B|A) = 0.8 and the
probability of Avi playing against an advanced player P(A) = 0.1.
We can calculate the probability of Avi losing a match P(B) with the law of total probability:
P(B) = P(B|A) \cdot P(A) + P(B|C) \cdot P(C) + P(B|D) \cdot P(D)
We know the probability of Avi losing to an intermediate player:
P(B|C) = 0.5, the probability of Avi
losing to a beginner player: P(B|D) =
0.1, the probability of an intermediate player being the
opponent: P(C) = 0.4, and the
probability of a beginner player being the opponent: P(D) = 0.5
Plugging in what we know into the law of total probability equation
we get: \begin{align*}
P(B) &= 0.8 \cdot 0.2 + 0.5 \cdot 0.4 + 0.1 \cdot 0.5 \\
&=0.08 + 0.2 + 0.05 \\
&= 0.33
\end{align*}
Or we can calculate P(B) by using
what we know in part A (67 \%). 1 - 0.67 = 0.33.
Back to Bayes’ theorem we have: \begin{align*}
P(A|B) &= \frac{0.8 \cdot 0.1}{0.33} \\
&= \frac{0.08}{0.33}\\
&= 0.24
\end{align*}
There is one box of bolts that contains some long and some short
bolts. A manager is unable to open the box at present, so she asks her
employees what is the composition of the box. One employee says that it
contains 60 long bolts and 40 short bolts. Another says that it contains
10 long bolts and 20 short bolts. Unable to reconcile these opinions,
the manager decides that each of the employees is correct with
probability \frac{1}{2}. Let B_1 be the event that the box contains 60
long and 40 short bolts, and let B_2 be
the event that the box contains 10 long and 20 short bolts. What is the
probability that the first bolt selected is long?
P(\text{long}) = \frac{7}{15}
We are given that: P(B_1)=P(B_2)=\frac{1}{2}P(\text{long}|B_1) = \frac{60}{60 + 40} =
\frac{3}{5}P(\text{long}|B_2) =
\frac{10}{10 + 20} = \frac{1}{3}
How many ways can one arrange the letters A, B, C, D, E such that A, B, and
C are all together (in any order)?
There are 3! \cdot 3!
permutations.
We can treat the group of A, B, and C (in
any order) as a single block of letters which we can call X. This will gurantee that any permutation we
find will satisfy our condition of having A, B, and
C being all together.
Our problem now has 3! = 6
permutations of our new letter bank: X,
D, and E.
XDEXEDDXEEXDDEXEDX
Let’s call these 6 permutations “structures”. For each of these
structures, there are 3! = 6
rearrangements of the letters A, B, and Cinside of X.
So, with 3! different arrangements
of D, E and our block of letters (X), and with each of those arrangements
individually having 3! ways to re-order
the group of ABC, the overall number of
permutations of ABCDE where ABC are all together, in any order, is 3! \cdot 3!.
Problem 5.3
Two chess players A and B play a series of chess matches against each
other until one of them wins 3 matches. Every match ends when one of the
players wins against the other, that is, the game does not ever
end in draw/tie. For example, one series of matches ends when the
outcomes of the first four games are: A
wins, A wins, B wins, A
wins. In how many different ways can the series occur?
There are 20 ways the series can be
won.
The series ends when the last game in the series is the third win by
either player. Overall, there must be at least 3 games to end a series
(all wins by the same player) and at most 5 games to end a series (each
player has two wins, and then a final win by either player) before
either player wins 3 games. Let’s assume player A always wins, and then we’ll multiply the
number of options by two to account for the possibilities where player
B wins instead.
Breaking it down:
For a series that ends in 3 games - there is a single option (all
wins by player A).
For a series that ends in 4 games, we’ve assumed the last game is
a player A win to end the series,
therefore the 3 preceding games have {3
\choose 2} options for player A
winning 2 of the 3 preceding games.
For a series that ends in 5 games, we’ve assumed the last game is
a player A win to end the series,
therefore the 4 preceding games have {4
\choose 2} options for player A
winning 2 of the 4 preceding games.
Overall, the number of ways the series can occur is: 2 \cdot (1 + {3 \choose 2} + {4 \choose 2}) =
20
Let’s say 1\% of the population has
a certain genetic defect.
Problem 6.1
A test has been developed such that 90\% of administered tests accurately detect
the gene (true positives). What needs to be the false positive rate
(probability that the administered test is positive even though the
patient doesn’t have a genetic defect) such that the probability that a
patient having the genetic defect given a positive result is 90\%?
The false positive rate should be \approx
0.001 to satisfy this condition.
Let A be the event a patient has a
genetic defect. Let B be the event a
patient got a positive test result.
We know:
P(A) = 0.01
The true positive rate (probability of a positive test result
given someone has the genetic defect) can be modeled by P(B|A)=0.9
The false positive rate (probability of positive test result
given someone doesn’t have the genetic defect) can be modeled by P(B|\bar{A}) = p
We want:
The probability that a patient having the genetic defect given a
positive result (P(A|B)) is 90\%
Let’s set up a relationship between what we know and what we want by
using Bayes’ Theorem:
We’ve found that the probability of a false positive (positive result
for someone who doesn’t have the genetic defect) needs to be \approx 0.001 to satisfy our condition.
Problem 6.2
A test has been developed such that 1\% of administered tests are positive when
the patient doesn’t have the genetic defect (false positives). What
needs to be the true positive probability so that the the probability a
patient has the genetic defect given a positive result is 50\%?
The probability of a true positive needs to be 0.99 to satisfy our condition.
Let A be the event a patient has a
genetic defect. Let B be the event a
patient got a positive test result.
We know:
P(A) = 0.01
The true positive rate (probability of positive test result if
someone has the genetic defect) can be modeled by P(B|A) = p
The false positive rate (probability of positive test result if
someone doesn’t have the genetic defect) can be modeled by P(B|\bar{A}) = 0.01
We can set up Bayes’ Theorem again to gain more information:
Rearranging the terms: \begin{aligned}
p & = 0.5 \cdot (p + 0.99)\\
0.5 \cdot p & = 0.5 \cdot 0.99 \\
p = P(B|{A}) &=0.99
\end{aligned}
We find that the probability of a true positive needs to be 0.99 to satisfy our condition.
Problem 6.3
1\% of administered tests are
positive when the patient doesn’t have the gene (false positives). Show
that there is no true positive probability such that the probability of
a patient having the genetic defect given a positive result can be 90\%.
Let A be the event a patient has a
genetic defect. Let B be the event a
patient got a positive test result.
We know:
P(A) = 0.01
The true positive rate (probability of positive test result if
someone has the genetic defect) can be modeled by P(B|A) = p
The false positive rate (probability of positive test result if
someone doesn’t have the genetic defect) can be modeled by P(B|\bar{A}) = 0.01
Rearranging the terms: \begin{aligned}
p & = 0.9 \cdot (p + 0.99)\\
0.1 \cdot p & = 0.9 \cdot 0.99 \\
p = P(B|{A}) &= \frac{0.99 \cdot 0.9}{0.1} = 8.91 > 1
\end{aligned}
We have found that p, a probability
value, must be greater than 1, which is impossible!
Given the rate of false positives, we cannot find a true positive
rate such that the probability of a patient having the genetic defect
given a positive result is 0.9.
The Avocado Cup is organized into rounds. In each round, players who
win advance to the next round, and players who lose are eliminated.
Rounds continue on like this until there is a single tournament
winner.
Define the following events in the sample space of possible outcomes
of the Avocado Cup:
A = Avi loses in the first
round.
B = Avi wins the
tournament.
C = Avi wins in the first
round.
Problem 7.1
Which of the following statements is true? Select all that
apply.
A and B are independent.
A and B are conditionally independent given C.
A, B, and C
form a partition of the sample space.
None of the above.
Only bubble 2: A and B are conditionally independent given C.
We know that A and B are not independent because winning or
losing the first match could affect if Avi wins the tournament.
It is helpful to think about “if C
happens does it affect my knowledge of A and B
happening”? If C happens we know that
A cannot happen. If A cannot happen then B is independent of A. This means A and B are
conditionally independent given C.
Recall a partition is a collection of non-empty, non-overlapping
subsets of a sample space. We know that A affects B,
which means that this statement cannot be true.
Since the third option is true the answer cannot be “None of the
above.”
Problem 7.2
The events A and B are mutually exclusive, or disjoint. More
generally, for any two disjoint events A and B,
show how to express P(\overline{A}|(A \cup
B)) in terms of P(A) and P(B)only. For this problem
only, show your work and justify each step.
There are several correct approaches to this problem. The simplest
one comes from using the definition of conditional probability to
write:
P(\overline{A}|(A \cup B)) =
\dfrac{P(\overline{A}\cap (A \cup B))}{P(A \cup B)} To evaluate
the numerator, notice that since A and
B are disjoint, any outcome that is not
in A but is in the union of A and B
(A or B) must be in B. The Venn diagram shown below illustrates
this. Therefore, we can simplify this as =
\dfrac{P(B)}{P(A \cup B)} and because we know A and B are
disjoint, we can use the addition rule to expand the denominator as
= \dfrac{P(B)}{P(A)+P(B)}
This is the desired final expression because it uses P(A) and P(B) only.
In the Venn Diagram below, \overline{A} is shaded in yellow, and A \cup B is shaded in blue. Their overlap,
\overline{A}\cap (A \cup B), is shaded
in green, which is just B.
Recall in the game Stringle, players try to guess a randomly
generated string. There is a new Stringle string available each day.
Each day’s Stringle string is a six-letter string,
where each letter is chosen uniformly at random, with
replacement, from among the 26 letters of the English alphabet.
This means Stringle strings can have repeated letters, and they do not
need to have any meaning as an English word.
For this problem, we’ll say that there are six vowels: A, E, I, O, U,
and Y. Consider the following three events:
A is the event that today’s
Stringle string starts with a vowel.
B is the event that today’s
Stringle string starts with a letter in the first half of the alphabet
(A through M, inclusive).
C is the event that today’s
Stringle string does not start with a Z.
Which of the following is true?
A and B are independent. A and B are
conditionally
A and B are independent. A and B are
conditionally dependent
A and B are dependent. A and B are
conditionally independent
A and B are dependent. A and B are
conditionally dependent
None of the above.
Bubble 1: A and B are independent. A and B are
conditionally dependent given C.
We can test if A and B are independent by using the equation:
\mathbb{P}(A \cap B) = \mathbb{P}(A) \cdot
\mathbb{P}(B).
We know \mathbb{P}(A) =
\frac{6}{26} because there are six vowels the Stringle string can
start with out of 26 letters in the
alphabet.
We know \mathbb{P}(B) = \frac{13}{26} =
\frac{1}{2} because the letters A through M is numbered 1 to 13, so
there are 13 possible letters out of
26.
We know \mathbb{P}(A \cap B) =
\frac{3}{26} because the letters A, E, and I are between A and M
and are also vowels out of all 26
letters.
When plugging these values into the equation we get:
\begin{align*}
\mathbb{P}(A \cap B) &= \mathbb{P}(A) \cdot \mathbb{P}(B) \\
\frac{3}{26} &= \frac{6}{26} \cdot \frac{1}{2} \\
\frac{3}{26} &= \frac{3}{26}
\end{align*}
This proves that A and B are independent.
Recall we can test if something is conditionally independent by doing
\mathbb{P}(A \cap B|C) = \mathbb{P}(A|C) \cdot
\mathbb{P}(B|C).
We know there are 25 letters in the
alphabet that are not equal to Z.
We can calculate \mathbb{P}(A|C) =
\frac{6}{25} because there are six vowels out of the 25 non-Z letters.
We can calculate \mathbb{P}(B|C) =
\frac{13}{25} because there are 13 letters out of the 25 non-Z letters.
We can calculate \mathbb{P}(A \cap B|C) =
\frac{3}{25} because the letters A, E, and I are between A and M
and are also vowels out of 25 non-Z
letters.
When plugging these values into the equation we get:
\begin{align*}
\mathbb{P}(A \cap B|C) &= \mathbb{P}(A|C) \cdot \mathbb{P}(B|C) \\
\frac{3}{25} &= \frac{6}{25} \cdot \frac{13}{25} \\
\frac{3}{25} &\neq \frac{78}{625}
\end{align*}
Since \mathbb{P}(A \cap B|C) \neq
\mathbb{P}(A|C) \cdot \mathbb{P}(B|C) this means that A and B are
conditionally dependent given C.
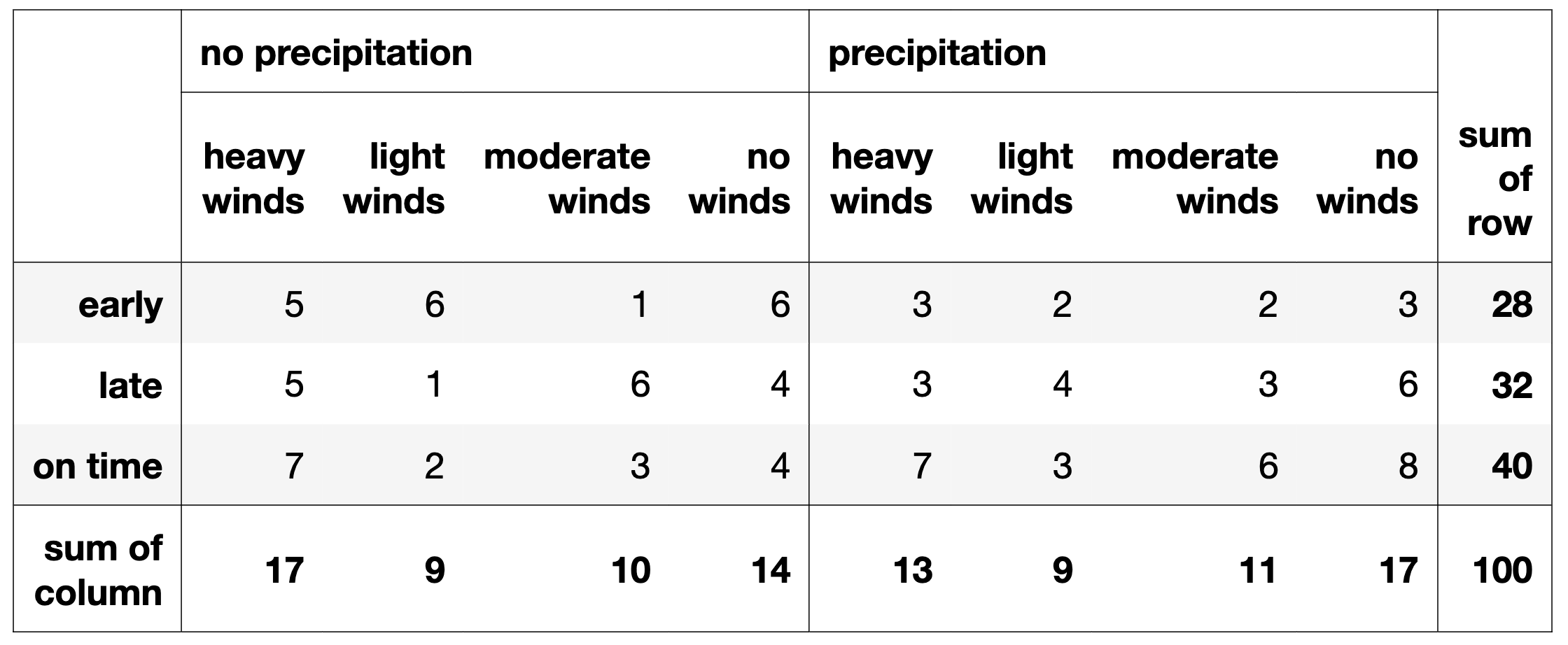
Delta’s flight operations center keeps track of weather conditions,
as they tend to impact whether or not flights are late. For each flight,
Delta keeps track of:
Whether or not there was precipitation — i.e.,
rain, snow, or hail.
The wind conditions — either no winds, light
winds, moderate winds, or heavy winds.
The flight’s status — whether it was early, on
time, or late.
Information about 100 flights is summarized in the table below.
For instance, we’re told that 6 flights in moderate winds and no
precipitation landed late, and that there were 13 total flights in heavy
winds and precipitation.
Delta would like to use this information to predict whether a new
flight will be early, on time, or late, given the weather
conditions.
There are 28 flights that landed
early, and of those, 5 + 3 = 8 were in
heavy winds, which means our estimate is \displaystyle\frac{8+1}{28+4} = \frac{9}{32}.
(The denominator is 28 + 4 since there are 4 possible wind conditions –
none, light, moderate, and heavy.)
For your convenience, the table from the previous page is repeated
again below.
Problem 9.3
An airline’s late-to-early ratio, given a set of weather conditions,
is defined as:
Using the assumptions of the Naïve Bayes classifier without
smoothing, show that Delta’s late-early ratio for flights in
heavy winds and precipitation is \bf{\frac{7}{5}}.
Hint: You’ll end up needing to compute 6 probabilities, one of
which you already found in part (a).
You have a large historical dataset of all competitors in past years
of the Avocado Cup chess tournament. Each year, hundreds of chess
players compete in the tournament, and one person is crowned the winner.
For each competitor in each year of the competition’s history, you have
information on their
whether or not they won the tournament that year (yes or
no).
Assume that birthdays of competitors are evenly distributed
throughout the months.
You want to predict who will win this year’s Avocado Cup. To do so,
you use this historical data to train a Naive Bayes classifier and
classify each competitor as a winner or non-winner, given their
experience level and birth month. Which of the following reasons best
explains why your classifier is ineffective in
identifying the winner?
Because it uses a variable (birth month) that likely has nothing to
do with a person’s chances of winning the tournament.
Because it uses a variable (experience level) that likely has a
strong connection with a person’s chances of winning the tournament.
Because it uses a dataset where there are many more non-winners than
winners.
Because it uses a categorical response variable.
Bubble 3: Because it uses a dataset where there are many more
non-winners than winners.
Each year there is only one winner, but then hundreds of non-winners!
This skews the data and makes it harder to figure out if someone won or
lost because of their birthday and level.
You’re interested in seeing the Milky Way in the night sky, which you
have sometimes been able to do when conditions are right. For each night
that you’ve attempted to see the Milky Way, you have a record of:
the setting (urban, suburban, or rural),
the season (winter, spring, summer, or fall),
the time (late night, or early morning), and
the outcome (successful, or unsuccessful).
These 12 attempts are recorded in
the table below.
setting
season
time
outcome
suburban
winter
late night
successful
rural
spring
late night
successful
urban
winter
early morning
successful
rural
winter
early morning
successful
rural
summer
late night
unsuccessful
urban
winter
late night
unsuccessful
rural
winter
early morning
unsuccessful
rural
spring
late night
unsuccessful
urban
fall
early morning
unsuccessful
suburban
summer
late night
unsuccessful
urban
winter
late night
unsuccessful
rural
winter
late night
unsuccessful
You want to use a Naive Bayes classifier to predict whether you’ll be
successful in seeing the Milky Way under the following conditions:
the setting is urban,
the season is winter, and
the time is late night.
Naive Bayes predicts that, under these conditions, the probability
you are unsuccessful is k times the
probability you are successful, for an integer value of k. What is k?
k=1
k=2
k=3
k=4
k=3
According to the Naive Bayes formula we will be solving these
equations: \begin{align*}
&P(\text{successful}|\text{urban, winter, late night})\\ &=
P(\text{successful}) * P(\text{urban}|\text{successful}) *
P(\text{winter}|\text{successful}) * P(\text{late
night}|\text{successful})
\end{align*} and \begin{align*}
&P(\text{unsuccessful}|\text{urban, winter, late night}) \\
&= P(\text{unsuccessful}) * P(\text{urban}|\text{unsuccessful}) *
P(\text{winter}|\text{unsuccessful}) * P(\text{late
night}|\text{unsuccessful})
\end{align*}
This means we need to calculate our prior probabilities P(\text{successful}), P(\text{unsucessful}), P(\text{urban}|\text{successful}), P(\text{urban}|\text{usuccessful}), P(\text{winter}|\text{successful}), P(\text{winter}|\text{unsuccessful}), P(\text{late night}|\text{successful}), and
P(\text{late
night}|\text{unsuccessful}).
We can calculate P(\text{successful}) by looking at the number
of successful outcomes from all possible outcomes. We find P(\text{successful}) = \frac{4}{12} =
\frac{1}{3}.
Similarily we can calculate P(\text{unsucessful}). P(\text{unsucessful}) = \frac{8}{12} =
\frac{2}{3}.
We can now calculate P(\text{urban}|\text{successful}) by looking
at how many settings are urban when the outcome is successful. P(\text{urban}|\text{successful}) =
\frac{1}{4}.
Similarily we can calculate P(\text{urban}|\text{unsuccessful}). P(\text{urban}|\text{unsuccessful}) =
\frac{3}{8}.
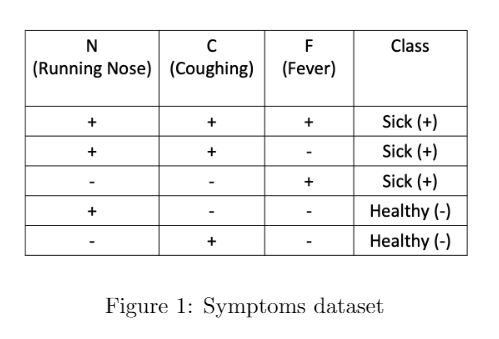
In the following "Symptoms" dataset, the task is to diagnose whether
a person is sick. We use a representation based on four features per
subject to describe an individual person. These features are "running
nose", "coughing", and "fever", each of which can take the value true
(‘+’) or false (‘–’).
Problem 12.1
What is the predicted class for a person with running nose but no
coughing, and no fever: sick, or healthy? Use a Naive Bayes
classifier.
The predicted class is Healthy(-).
If p_+ and p_- are the numerators of the Naive Bayes
comparison that represent a Sick(+)
prediction and a Healthy(-) prediction,
respectively, we have to compare: \begin{aligned}
p_+=P(N,\bar C,\bar F|+)P(+)\quad \text{and}\quad p_-=P(N,\bar
C,\bar F|-)P(-).
\end{aligned}
Then we can build up our comparison: \begin{aligned}
p_+&= P(+)P(N,\bar C,\bar F|+) =
\frac35\times\frac{2}{27}=\frac{2}{45}\quad \\
p_-&= P(-)P(N,\bar C,\bar F|-) =
\frac25\times\frac{1}{4}=\frac{1}{10}\\
p_-&>p_+
\end{aligned}
So, the predicted class is Healthy(-).
Problem 12.2
What is the predicted class for a person with a running nose and
fever, but no coughing? Use a Naive Bayes classifier.
The predicted class is Sick(+).
From the dataset we see P(F|-)=0, so
we know: P(N,\bar C, F|-)=P(N|-)P(\bar
C|-)P(F|-)=0
This will make p_- = P(N,\bar C, F|-)P(-) =
0
Contrast this against P(F|+),
P(N|+), and P(\bar C|+), which
are all nonzero values, making P(N,\bar C,
F|+), (and therefore p_+)
nonzero.
So p_+>p_-. This means our
predicted class is Sick(+).
Problem 12.3
To deal with cases of unseen features, we used “smoothing" in class.
If we use the”smoothing" method discussed in class, then what is the
probability of a person having running nose and fever, but no coughing
if that person was diagnosed “healthy"?
With smoothing, the result is \dfrac{1}{16}.
To apply smoothing, we add 1 to the
numerator, and add the number of possible categories of the given event,
healthiness (which would be 2 possible
options in this case: sick, or healthy) to the denominator of our
conditional probabilities. That way, other probabilities avoid
being multiplied by zero. Let’s smooth our three conditional
probabilities:
In part (a), what are the odds of a person being
“sick" who has running nose but no coughing, and no fever? (Hint:
the formula for the odds of an event A
is \text{odds}(A) = \frac{P(A)}{1 -
P(A)})
\text{Odds of being
sick}=\frac27
Using previous information, we have that the probability of a person
being sick with a running nose but no coughing and no fever is:
\begin{aligned}
\text{Odds of being sick}=\frac{P(+|N,\bar C,\bar F)}{1-P(+|N,\bar
C,\bar F)}=\frac27.
\end{aligned}
Problem 12.5
Say someone fit a logistic regression model to a dataset containing
n points (x_1,y_1),(x_2,y_2),\cdots,(x_n,y_n) where
x_is are features and y_i\in\{-1,+1\} are labels. The estimated
parameters are w_0,~w_1, that is, given
feature x, the predicted probability of
belonging to class y=+1 is
With the help of the Alien from Bayesian Galaxy, Issac built a Little
Hadron Collider in his garage to continue testing some fundamental
principles of nature. The alien set up a fixed target at one end of the
collider, and ask Issac to shoot quarks from the other end. Everytime
the quark hit the target, the Alien will tell Issac whether a new hadron
is formed or not. Due to the energy limitation in Issac’s garage, he
could only generate up, down, top, and bottom quarks (Strange and Charm
quark would have consumed too much energy). For each quark Issac
created, he has a record of:
the type up, down, top,
bottom
the state particle,
antiparticle
the color charge red, green,
blue, and
the outcome hadron formed,
hadron not formed
Issac created 10 quarks, and these
10 quarks are recorded in the table
below.
type
state
color
Formed Hadron
down
particle
green
formed
top
particle
red
formed
top
antiparticle
blue
formed
up
particle
red
formed
up
antiparticle
blue
formed
bottom
antiparticle
red
not formed
down
antiparticle
blue
not formed
down
particle
blue
not formed
top
particle
green
not formed
up
antiparticle
green
not formed
Since the alien is from Bayesian galaxy, they want Issac to develop a
Naive Bayes classifier to predict whether he’ll be successful in forming
a hadron under the following quark conditions:
the type is up
the state is particle
the color is blue
Problem 13.1
Naive Bayes predicts that, given a up-particle-blue
quark, the probability a hadron formed is k times the probability a hadron is not
formed, for an integer value of k. What
is k?
1
2
3
4
k = 3
Following the equation for Naive Bayes we will create the folllowing
two formulas: \begin{align*}
&P(\text{formed hadron}|\text{up, particle, blue})\\
&=P(\text{formed hadron}) * P(\text{up}|\text{formed hadron}) *
P(\text{particle}|\text{formed hadron}) * P(\text{blue}|\text{formed
hadron})
\end{align*} and \begin{align*}
&P(\text{not formed hadron}|\text{up, particle, blue})\\
&=P(\text{not formed hadron}) * P(\text{up}|\text{not formed
hadron}) * P(\text{particle}|\text{not formed hadron}) *
P(\text{blue}|\text{not formed hadron})
\end{align*}
Now all we have to do is calculate the prior probabilities!
We can calculate P(\text{formed
hadron}) by looking at the number of times a
formed hadron happens out of the total number of outcomes.
We can see this probability is P(\text{formed
hadron}) = \frac{5}{10} = \frac{1}{2}.
Similarily we can calculate for a not formed hadronP(\text{not formed hadron}) = \frac{5}{10} =
\frac{1}{2}.
We can calculate P(\text{up}|\text{formed
hadron}) by looking at the number of times up
appears out of all formed hadrons. This will give us
something like: P(\text{up}|\text{formed
hadron}) = \frac{2}{5}.
We can use this same method to calculate P(\text{up}|\text{not formed hadron}) by
looking at the number of times up appears out of all
not formed hadrons. P(\text{up}|\text{not formed hadron}) =
\frac{1}{5}
If you continue finding the conditional probabilities you will
find:
P(\text{particle}|\text{not formed
hadron}) = \frac{2}{5}
P(\text{blue}|\text{formed hadron}) =
\frac{2}{5}
P(\text{blue}|\text{not formed hadron}) =
\frac{2}{5}
Now we simply plug and chug using the equations we had before! \begin{align*}
&P(\text{formed hadron}|\text{up, particle, blue})\\
&= P(\text{formed hadron}) * P(\text{up}|\text{formed hadron}) *
P(\text{particle}|\text{formed hadron}) * P(\text{blue}|\text{formed
hadron})\\
&= \frac{1}{2} * \frac{2}{5} * \frac{3}{5} * \frac{2}{5}\\
&= \frac{6}{125}
\end{align*} and \begin{align*}
&P(\text{not formed hadron}|\text{up, particle, blue})\\
&= P(\text{not formed hadron}) * P(\text{up}|\text{not formed
hadron}) * P(\text{particle}|\text{not formed hadron}) *
P(\text{blue}|\text{not formed hadron})\\
&= \frac{1}{2} * \frac{1}{5} * \frac{2}{5} * \frac{2}{5}\\
&= \frac{2}{125}
\end{align*}
Now the only thing left to do is calculate k. We can do this by solving the equation
k * \frac{2}{125} = \frac{6}{125}. You
should find k=3.
Problem 13.2
What would be the value of k if you
change up quark in the previous collision to
top quark, but keep everything else the same (i.e.
top-particle-blue quark)?
1
2
3
4
k = 3
All we have to do for this problem, after completing the first part,
is to see how P(\text{top}|\text{formed
hadron}) and P(\text{top}|\text{not
formed hadron}) changes our previous equations.
We calculate these two probabilites by looking at the number of
formed/not formed hadrons respectively and counting how many of those
are in the top position. You will find P(\text{top}|\text{formed hadron}) =
\frac{2}{5} and P(\text{top}|\text{not
formed hadron}) = \frac{1}{5}. These are the same as our
conditional probabilities when in the up position! Which
means k=3 again.
If you want to go through the entire calculation again it can be
found below: \begin{align*}
&P(\text{formed hadron}|\text{top, particle, blue})\\
&= P(\text{formed hadron}) * P(\text{top}|\text{formed hadron}) *
P(\text{particle}|\text{formed hadron}) * P(\text{blue}|\text{formed
hadron})\\
&= \frac{1}{2} * \frac{2}{5} * \frac{3}{5} * \frac{2}{5}\\
&= \frac{6}{125}
\end{align*} and \begin{align*}
&P(\text{not formed hadron}|\text{top, particle, blue})\\
&= P(\text{not formed hadron}) * P(\text{top}|\text{not formed
hadron}) * P(\text{particle}|\text{not formed hadron}) *
P(\text{blue}|\text{not formed hadron})\\
&= \frac{1}{2} * \frac{1}{5} * \frac{2}{5} * \frac{2}{5}\\
&= \frac{2}{125}
\end{align*}
We can do this by solving the equation k *
\frac{2}{125} = \frac{6}{125}. You should find k=3.
Delta’s flight operations center keeps track of weather conditions,
as they tend to impact whether or not flights are late. For each flight,
Delta keeps track of:
Whether or not there was precipitation — i.e.,
rain, snow, or hail.
The wind conditions — either no winds, light
winds, moderate winds, or heavy winds.
The flight’s status — whether it was early, on
time, or late.
Information about 100 flights is summarized in the table below.
For instance, we’re told that 6 flights in moderate winds and no
precipitation landed late, and that there were 13 total flights in heavy
winds and precipitation.
Delta would like to use this information to predict whether a new
flight will be early, on time, or late, given the weather
conditions.
There are 28 flights that landed
early, and of those, 5 + 3 = 8 were in
heavy winds, which means our estimate is \displaystyle\frac{8+1}{28+4} = \frac{9}{32}.
(The denominator is 28 + 4 since there are 4 possible wind conditions –
none, light, moderate, and heavy.)
For your convenience, the table from the previous page is repeated
again below.
Problem 14.3
An airline’s late-to-early ratio, given a set of weather conditions,
is defined as:
Using the assumptions of the Naïve Bayes classifier without
smoothing, show that Delta’s late-early ratio for flights in
heavy winds and precipitation is \bf{\frac{7}{5}}.
Hint: You’ll end up needing to compute 6 probabilities, one of
which you already found in part (a).